General system performance
General system performance
Books
- Systems Performance: Enterprise and the Cloud - Brendan Gregg (En)
- The Art of Application Performance Testing - Ian Molyneaux (En)
Talks
- Нагрузочное тестирование типичного интернет-сервиса - Андрей Похилько (Rus)
- От сервиса нагрузочного тестирования к центру компетенций - Урал Нургалин (Rus)
- Сложности performance-тестирования - Андрей Акиньшин (Rus)
- Честное перформанс-тестирование - Дмитрий Пивоваров (Rus)
- Бутылочное горлышко - Михаил Епихин (Rus)
- Учимся анализировать результаты нагрузочного тестирования - Алексей Лавренюк (Rus)
- Ускоряем Apache JMeter - Вячеслав Смирнов (Rus)
- Cloud Performance Root Cause Analysis at Netflix - Brendan Gregg (En)
- Linux Performance - Brendan Gregg (En)
- Подводные камни в нагрузочном тестировании - Владимир Ситников (Rus)
- Нагрузочное тестирование Atlassian Jira - Алексей Матвеев (Rus)
Articles
Analyzing performance methods
Java application performance
Books
Talks
- Java Benchmarking: как два таймстампа прочитать! - Алексей Шипилёв (Rus)
- Перформанс: Что В Имени Тебе Моём? - Алексей Шипилёв (Rus)
Data analysis
Books
База знаний нагрузочного тестирования
Материал в процессе наполнения и редактирования
Что такое нагрузочное тестирование?
- Глоссарий
- Введение в теорию НТ
- Виды тестов
- Профиль нагрузки
- Доклады по теме
Разработка тестовых скриптов и заглушек
- Примеры скриптов Apache JMeter
- Примеры скриптов Gatling
- Плагины Apache JMeter
Документация
Запуск тестов
Сбор и анализ метрик/логов
Генерация тестовых данных
Изучение работы системы
Настройка стенда
Инструменты нагрузочного тестирования
Мониторинг
Подготовка рабочего места
Автоматизация
- Доклады
Что такое нагрузочное тестирование?
Глоссарий
- ISTQB - англоязычный глоссарий терминов Iternation Software Testing Qualifications Board. К сожалению есть ряд спорных терминов и определений, которые либо не раскрывают суть, либо противоречат другим источникам.
- RSTQB - аналогичный предыдущему русскоязычный глоссарий Russian Software Testing Qualifications Board
Введение в теорию НТ
Нагрузочное тестирование (НТ) — тип тестирования, в котором мы проверяем, соответствует ли наша система поставленным нефункциональным требованиям при работе под высокой нагрузкой.
По сравнению с функциональным тестированием, НТ сложнее чем просто тестирование, выдающее как результат успех/ошибка. Оно намного сложнее и результаты — это множество метрик и графиков, которые должны быть проанализированы чтобы можно было сделать вывод, насколько хорошо система работает в разных ситуациях.
Что нужно для НТ
Требования
Требования должны быть максимально конкретны и покрывать множество ситуаций.
Пример плохого требования — «страницы должны загружаться быстро».
Пример хорошего требования — «такая-то страница должна открывать быстрее чем за 100 мс для 75% случаев, быстрее 500 мс для 95% случаев и быстрее 1 с для 99% случаев».
Специалисты
Чем больше масштаб — тем сильнее разделение на более узкие специализации, но в общем для инженеров НТ было необходимо иметь следующие роли:
- QA — уметь искать проблемные места и выстраивать процесс обеспечения качества.
- Аналитик — уметь выявлять причинно-следственные связи, исследовать паттерны поведения пользователей и разбираться в сложных системах.
- Разработчик — уметь проектировать и программировать средства автоматизации и тестовые сценарии.
- DevOps — уметь ориентироваться в архитектуре тестового окружения и модифицировать его.
Инструменты
- Генератор нагрузки: JMeter, Gatling, k6, Locust ….
- Средства управления кластером (AWS API и подобное, собственные инструменты и т.д.).
- Средства мониторинга и средства хранения и визуализации метрик и логов (Prometheus/InfluxDB + Grafana, ELK etc).
- Средство для составления и место хранения отчётов.
- Инструменты командной строки, электронные таблицы и т.д.
Тестовое окружение
Тестовое окружение включает в себя:
- Целевая система — должна быть как можно ближе к проду, а именно соответствовать его аппаратным ресурсам (CPU, RAM etc), базам данных (хотя бы по объёму etc)
- Кластер подачи нагрузки — с размещёнными генераторами нагрузки и средствами мониторинга
Этапы
- Формулировка требований (что требуется от системы?).
- Подготовка сценария (как будем воспроизводить проверяемое поведение пользователей и какие метрики приложения будем собирать?).
- Подготовка тестового окружения (на чём будем тестировать и какие системные метрики будем собирать?).
- Проведение теста и измерения (каковы значения собираемых метрик?).
- Анализ (соответствует ли система требованиям, какие есть проблемы и что их вызывает?).
- Отчёт (какие знания мы получили?).
- План доработки системы* (как устранить проблемы?) — не всегда в компетенции НТ, лучше спросить функциональные команды или DevOps/SRE команду.
Этапы автоматизации
- «Ручной» запуск (целевая система, тестовый сценарий и кластер подачи нагрузки запускаются вручную, результаты собираются вручную)
- Тесты запускаются с минимальной автоматизацией (один скрипт/набор скриптов и целевую системы с кластером подачи нагрузки поднимают и сценарий запускают и результаты собирают).
- Тесты вручную запускаются через веб интерфейс для определённой версии софта + создаётся красивый отчёт.
- Интеграция в CI/CD.
- Деградационные тесты.
- Роботы делают всю рутину, люди сфокусированы только на по-настоящему сложных ситуациях более исследовательского характера: профилирование, хаос-тестинг и т.д.
Главные метрики и их анализ
Как было сказано во введении, мы должны собирать специфические для сценария и общие для системы метрики. Инженеры из Google поделились своим опытом и описали «4 золотых сигнала», которые являются группами метрик, которые покрывают практически всё что нам нужно анализировать:
- Латентность.
- Трафик.
- Ошибки.
- Насыщенность.
Далее описаны эти типы метрик с дополнительными пояснениями для некоторых из них.
Латентность
Это время обработки запроса, от момента отправки запроса клиентом до получения ответа им. Низкая латентность — пользователь доволен. Латентность успешных запросов должна быть отделена от латентности ошибочных. Ошибки могут возвращаться очень быстро (просто из-за потери соединения с базой данных например) и это может значительно влиять на статистику. Медленные ошибочные запросы ещё хуже.
Эта метрика это то, что пользователь замечает в первую очередь (если система вообще доступа, хах), поэтому мы разберём её немного более подробно.
Среднее и отклонения
От системы требуется быстро и правильно отвечать на запросы пользователей. И если правильность ответов скорее относится к функциональному тестированию, скорость является как раз нашей заботой. Но «система должна отвечать быстро» — слабое требование. Давайте разберёмся почему. Если мы посмотрим на этот график времени ответа ниже, мы не сможем сказать, насколько быстро отвечает система при заданной нагрузке:
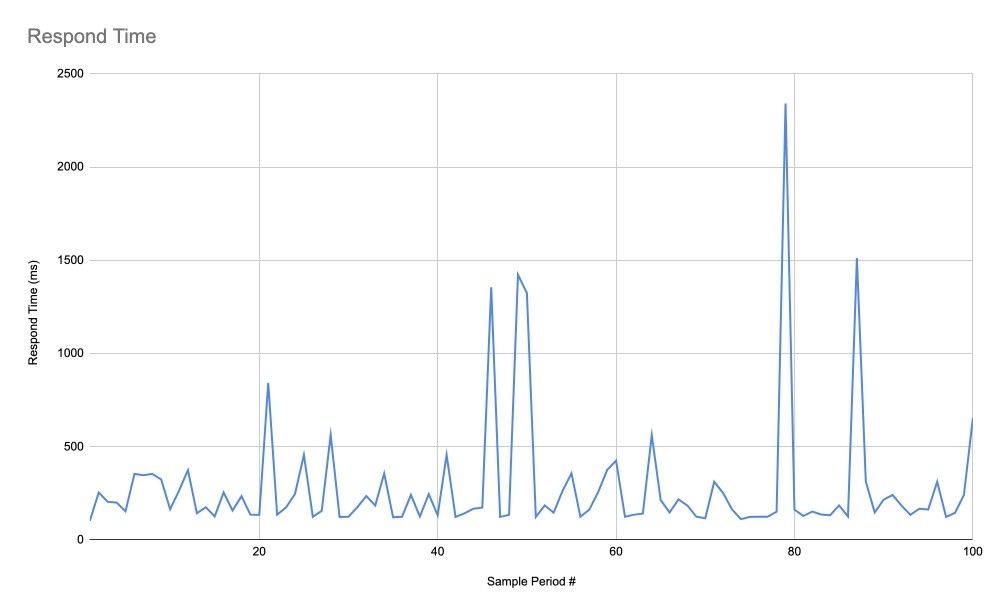
Мы можем проверить среднее время ответа, но если мы смотрим только на это среднее, мы можем сделать неверные выводы. Например, на графике ниже среднее время ответа может быть вполне удовлетворительным для нас (284 мс), но это не говорит нам ничего о скачках, которые существуют и могут быть критичны для нас:
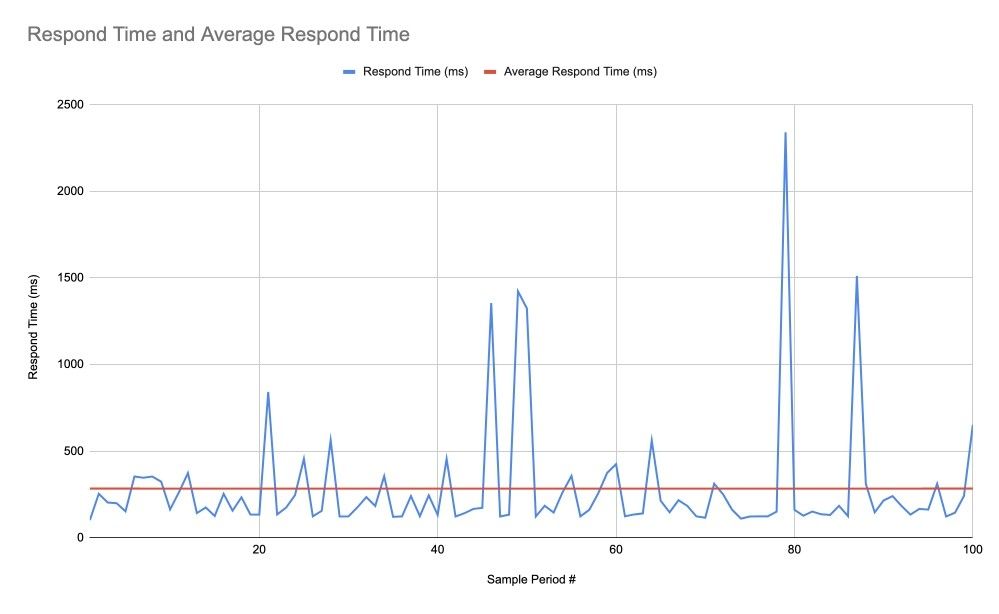
Стандартное отклонение (или дисперсия == квадрат стандартного отклонения) может помочь нам. На следующем графике мы видим среднее значение (красная линия) плюс (жёлтая линия) или минус (зелёная линия) стандартное отклонение. На самом деле среднее значение минус стандартное отклонение в нашем случае отрицательное, но это не имеет смысла, поэтому эта величина принимается за ноль.
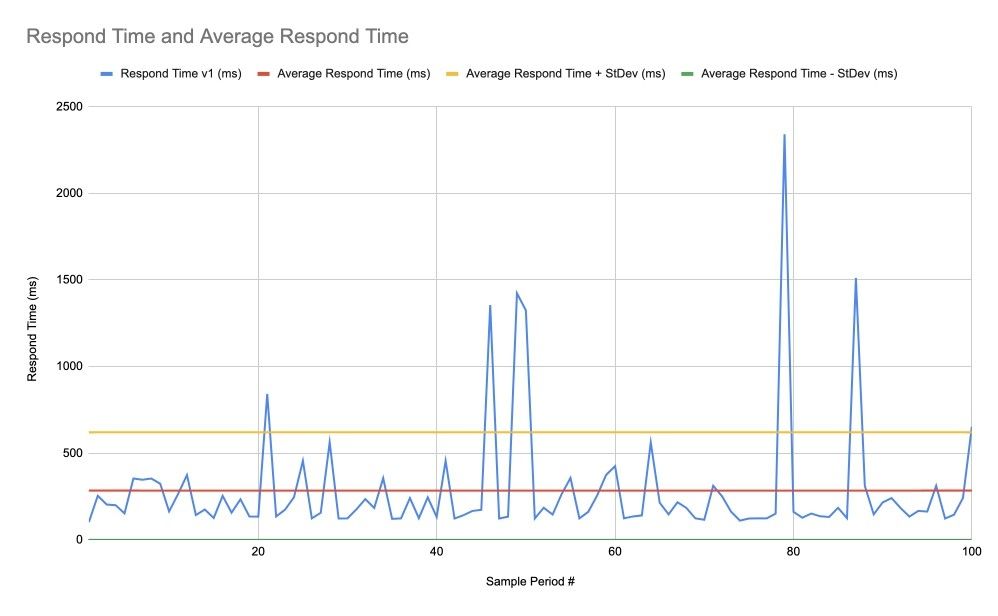
Теперь мы видим некоторую оценку, говорящую нам о некоторой изменчивости. Но так же как среднее значение не очень показательно, стандартное отклонение, являясь «усреднённой изменчивостью» не очень подходит для всех распределений случайных величин. Оно хорошо для нормального распределения, но наше время ответов не обязательно является нормально распределённым.
Перцентили
Перцентили подходят значительно лучше. Но чтобы использовать их, нужно сформулировать несколько требований. Например, 50% запросов должны выполняться менее чем за 100 мс, 95% менее чем за 400 мс и 99% менее чем за 1 с. Ниже показан пример графика, где отображены эти перцентили и можно увидеть, насколько время ответов соответствует требованиям, просто сравнив значения процентилей с требуемым:

Как видно, перцентили больше чем в наших требованиях.
Сравнение нескольких версий
Теперь предположим что мы сделали две оптимизированные версии. Сравним с изначальным графиком:
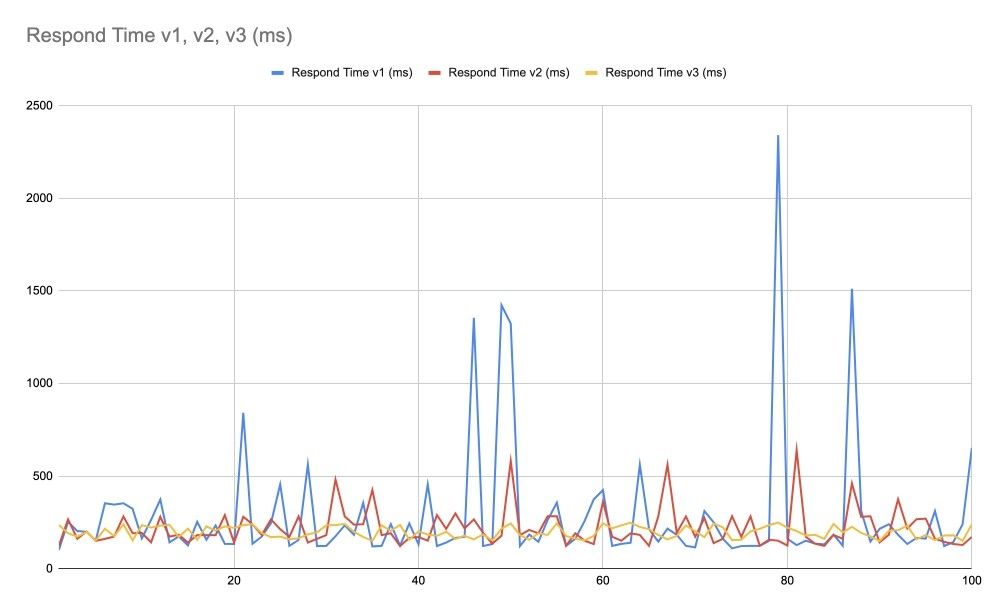
Глядя на график времени ответов мы конечно можем сказать, что красная линия v2 выглядит лучше чем синяя v1, а жёлтая v3 выглядит лучше чем красная v2. Но нам нужно не просто примерно сказать что лучше, но определить это с уверенностью, а лучше ещё и вычислить, насколько лучше. Для этого мы можем отсортировать времена ответов и получить такой график:
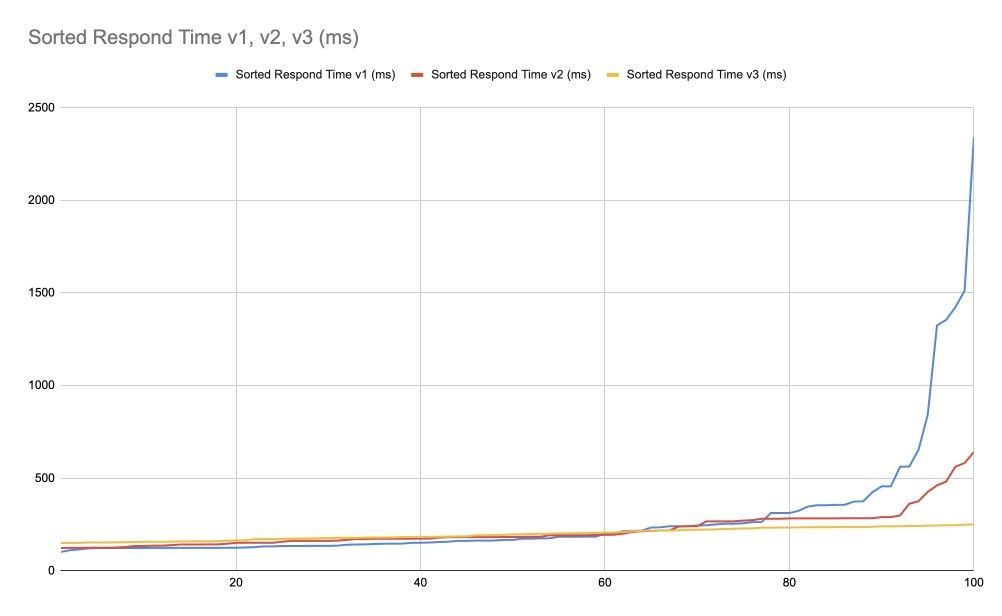
Этот график позволяет нам проще работать с процентилями. Обратите внимание, здесь у нас 100 замеров и поэтому мы можем не агрегировать данные для перцентилей, но в реальном случае вам это понадобится.
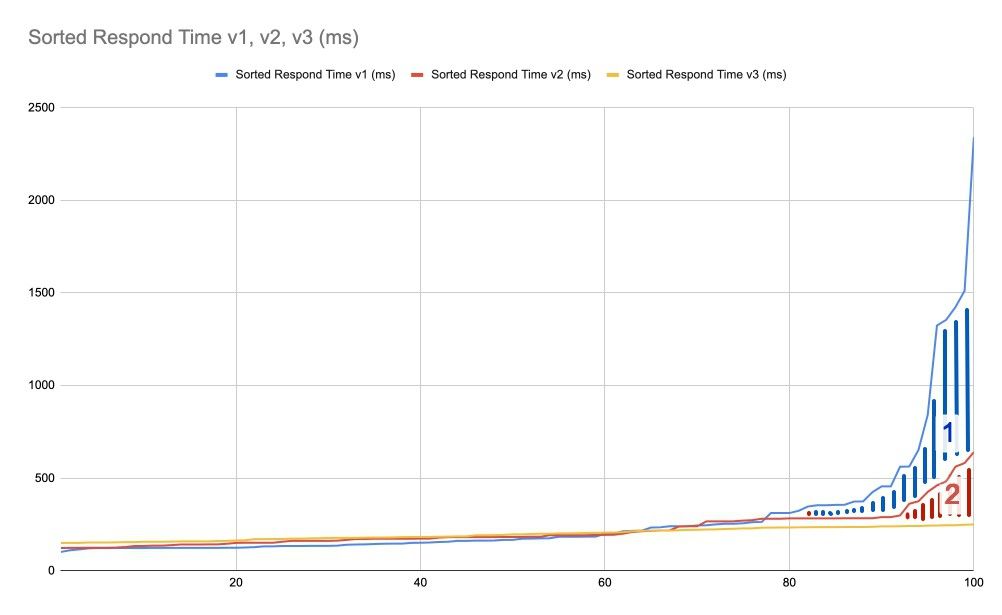
Теперь мы явно можем сказать, что жёлтая линия v3 это лучший вариант, но насколько лучший? Чтобы ответить на этом, мы можем посчитать (проинтегрировав значения точек графиков) площади, отмеченные «1» и «2» на графике ниже. Площадь «1» показывает, насколько v2 лучше чем v1, площадь «2» — насколько v3 лучше v2, а сумма «1» и «2» — насколько v3 лучше v1.
APDEX
APDEX (англ. Application Performance inDEX – индекс производительности приложения) — открытый стандарт, который определяет метод для оценки и сравнения множества показателей от времени ответа приложения до качества еды и многого другого.
Пример применения APDEX – автоматизированное сравнение результатов нескольких запусков тестов.
Представим, что у нас есть график времени ответа какого-нибудь эндпоинта. И есть график для второй версии алгоритма того же эндпоинта. Посмотрим на них вместе:
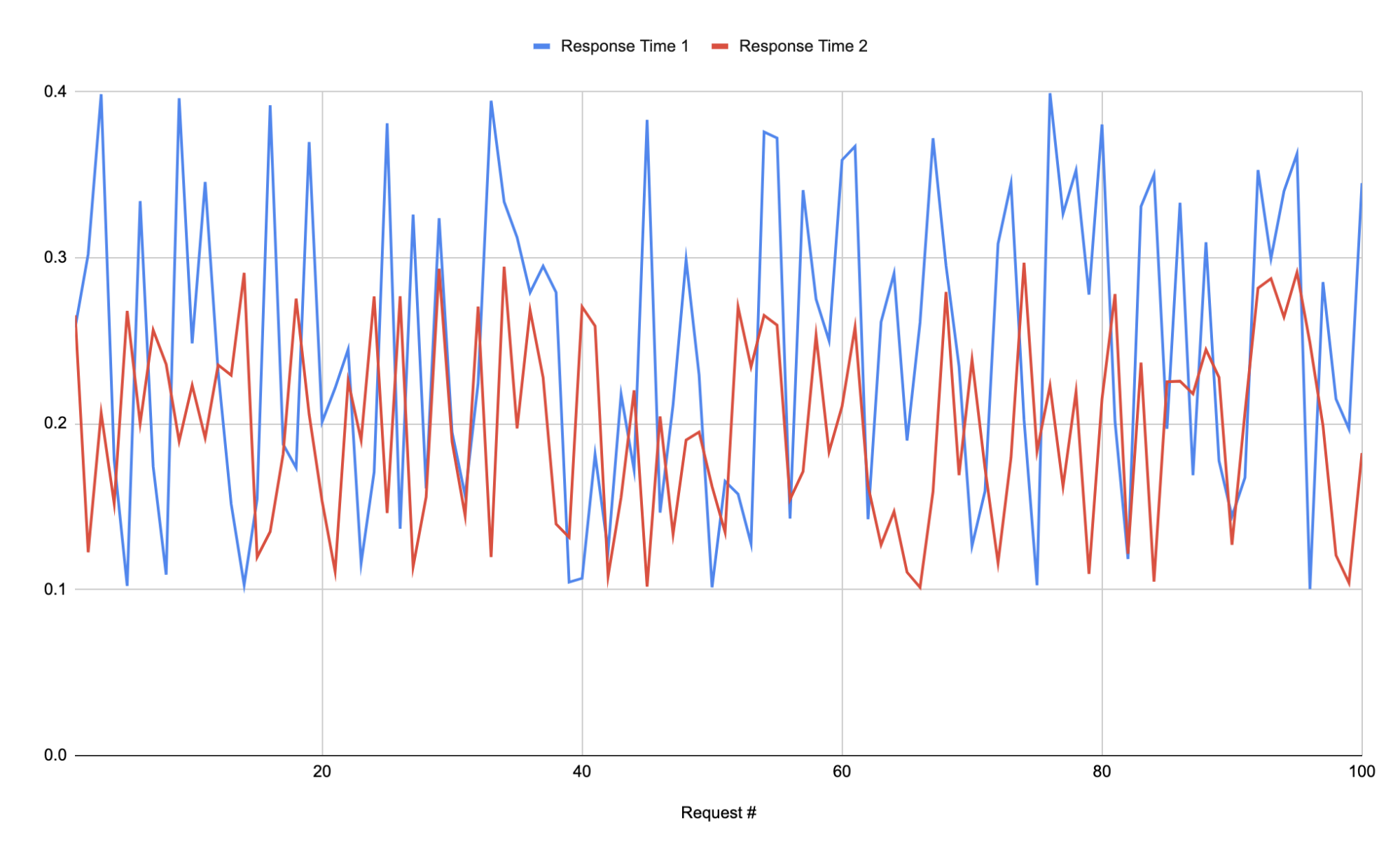
Конечно вроде видно что красная линия лучше, но это видно человеку, а машине? Можно использовать перцентили, а можно APDEX.
Вот схема его расчёта:
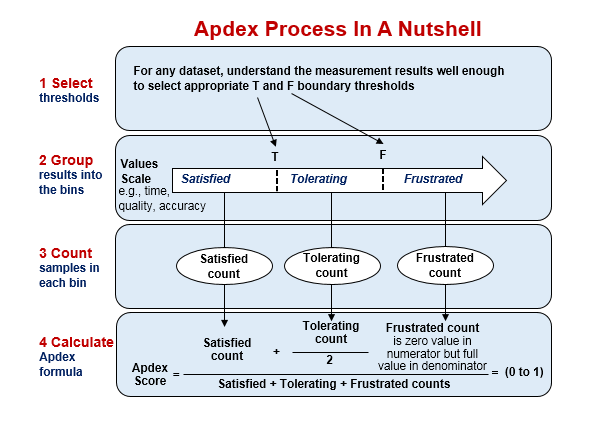
Примем следующую градацию:
- удовлетворительное (satisfied) время: <=200 ms
- терпимое (tolerating) время: <=300 ms
- неудовлетворительное (frustrated) время: >300 ms
и применим к нашим данным.
Получится (поверьте):
- Первая версия (синяя линия) – 0.525
- Вторая версия (красная линия) – 0.75
APDEX уровни:
- 0.00..0.50 — неприемлемо
- 0.50..0.70 — неудовлетворительно
- 0.70..0.85 — удовлетворительно
- 0.85..0.94 — хорошо
- 0.94..1.00 — отлично
Просто, измеримо, сравнимо. Не так просто интерпретировать как перцентили, но тем не менее.
Трафик
Для традиционных API трафик может быть измерен показателем числа запросов в секунду (англ. requests per second, RPS). Высокий RPS (при низком времени ответа) — много довольных клиентов. Может быть полезным различать RPS статических и динамических ресурсов. Для стриминговых систем можно мониторить частоту ввода/вывода и число параллельных сессий. Для хранилищ ключ-значение — число транзакций и запросов в секунду.
Ошибки
Очевидно, что мало ошибок — это хорошо (при низком времени ответа и объёмном трафике). Но коды протокола HTTP могут быть недостаточны для выражения всех статусов. Например, HTTP-200 может быть выслан для ответа с неверным содержимым. А HTTP-500 от балансировщика может быть как ошибкой балансировщика так и ошибкой на воркере и важно различать эти ситуации. Хотя нагрузочное тестирование это не функциональное тестирование, всё равно может быть важно проверять ситуацию глубже, чем просто смотреть на HTTP коды, чтобы убедиться что система не просто работает быстро, но и корректно.
Насыщенность
Показывает, насколько «заполнены» ваши сервера и система в целом. К этому типу относится множество метрик, вот некоторые:
- Загруженность CPU.
- Количество свободной памяти.
- Количество свободного места на диске.
- Показатели ввода/вывода, в том числе сетевого.
- Число использованных дескрипторов.
- Количество серверов-воркеров.
Виды тестов
Смоук тесты
Простейшие тесты, предназначены просто для проверки, что тест работает на нужной конфигурации и мы собираем все нужные метрики. Небольшая нагрузка, короткое время работы.
Закрытая и открытая модели тестирования
- Закрытая — пользователи ждут завершения предыдущих запросов прежде чем отправлять следующие. Это вэб подобие обычного магазина с несколькими продавцами и очередью покупателей.
- Открытая — пользователи приходят и приходят без ожидания завершения обработки предыдущих запросов. Это настоящий вэб.
Тесты на объём нагрузки
При тестах на объём нагрузки (volume тесты) мы проверяем в нашей системе время ответа и другие метрики, описанные в разделе «Главные метрики», при определённом объёме нагрузки, то есть при определённой частоте запросов и таком их распределении, которое соответствует реальному использованию системы. Этот объём задаётся требованиями к системе и обычно соответствует некоторым ожиданиям будущего уровня нагрузки на систему, который мы должны выдержать, обеспечив комфортные параметры работы для пользователей.
Тесты на пределы
Допустим наша система соответствует требованиям и сервера отвечают достаточно быстро для определённого ожидаемого числа пользователей. Теперь мы хотим пойти дальше ожидаемого объёма нагрузки и проверить, сможет ли наша система обслуживать значительно большее число пользователей при том же профиле нагрузки, что мы видим на проде. Для этого мы постепенно увеличиваем нагрузку на наш сервис и смотрим на метрики чтобы найти точку, при которой система перестаёт работать достаточно хорошо. Здесь на графике показана 95% персентиль времени ответа на один из типов запросов относительно моделируемого числа пользователей:
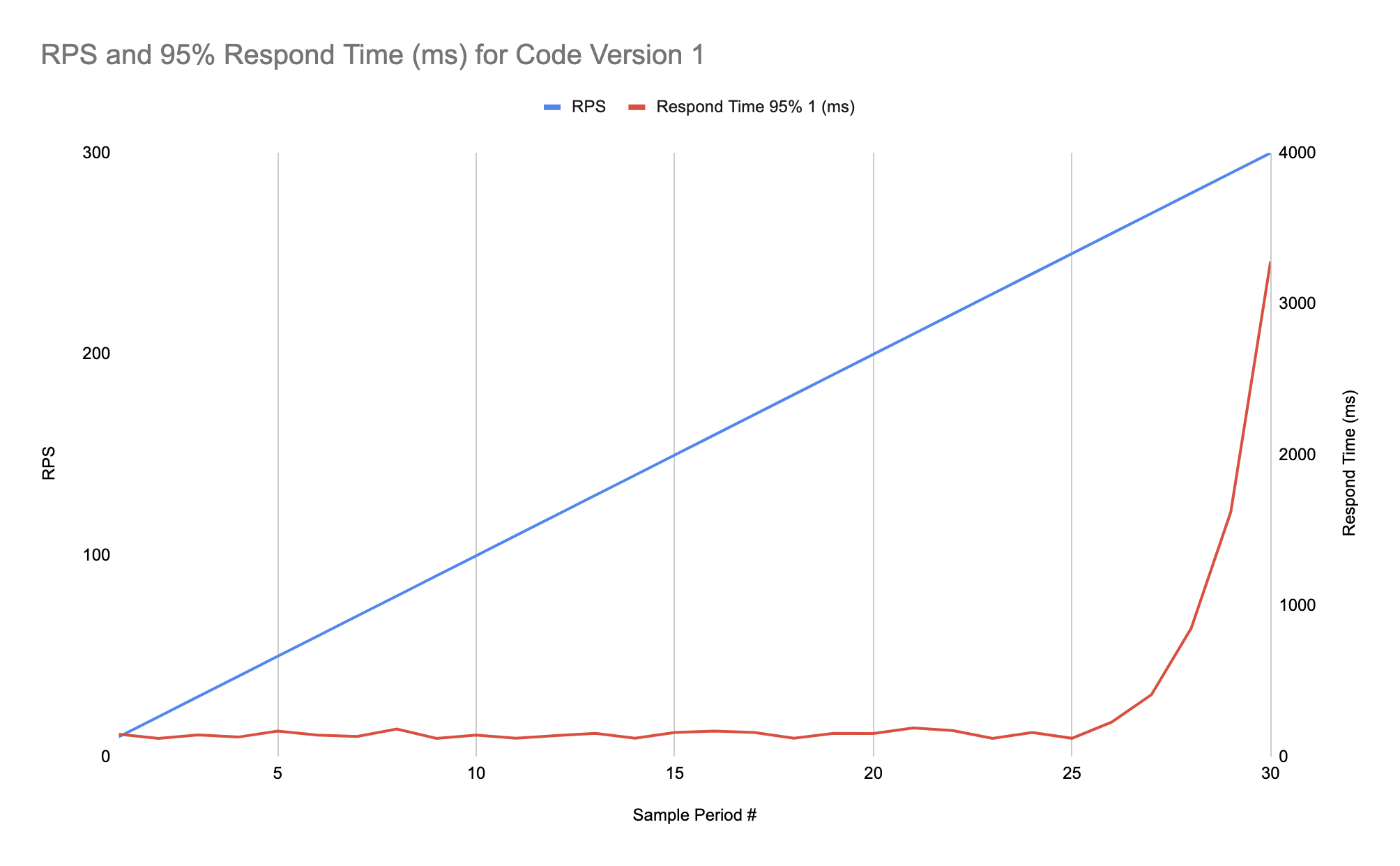
Как мы видим здесь время ответа начинает сильно расти при нагрузке свыше примерно 250 пользователей (у нас в этом примере очень простая система, да). Поэтому мы решили немного улучшить нашу систему и конечно нам нужно сравнить две версии. Чтобы это сделать мы строим результаты на том же графике что был для первой версии, только добавляем тоже 95%-ю персентиль для второй версии. Всякое может быть, например мы можем получить улучшенное время ответа для высоких нагрузок, но потерять скорость при низких нагрузках, как показано на графике ниже:
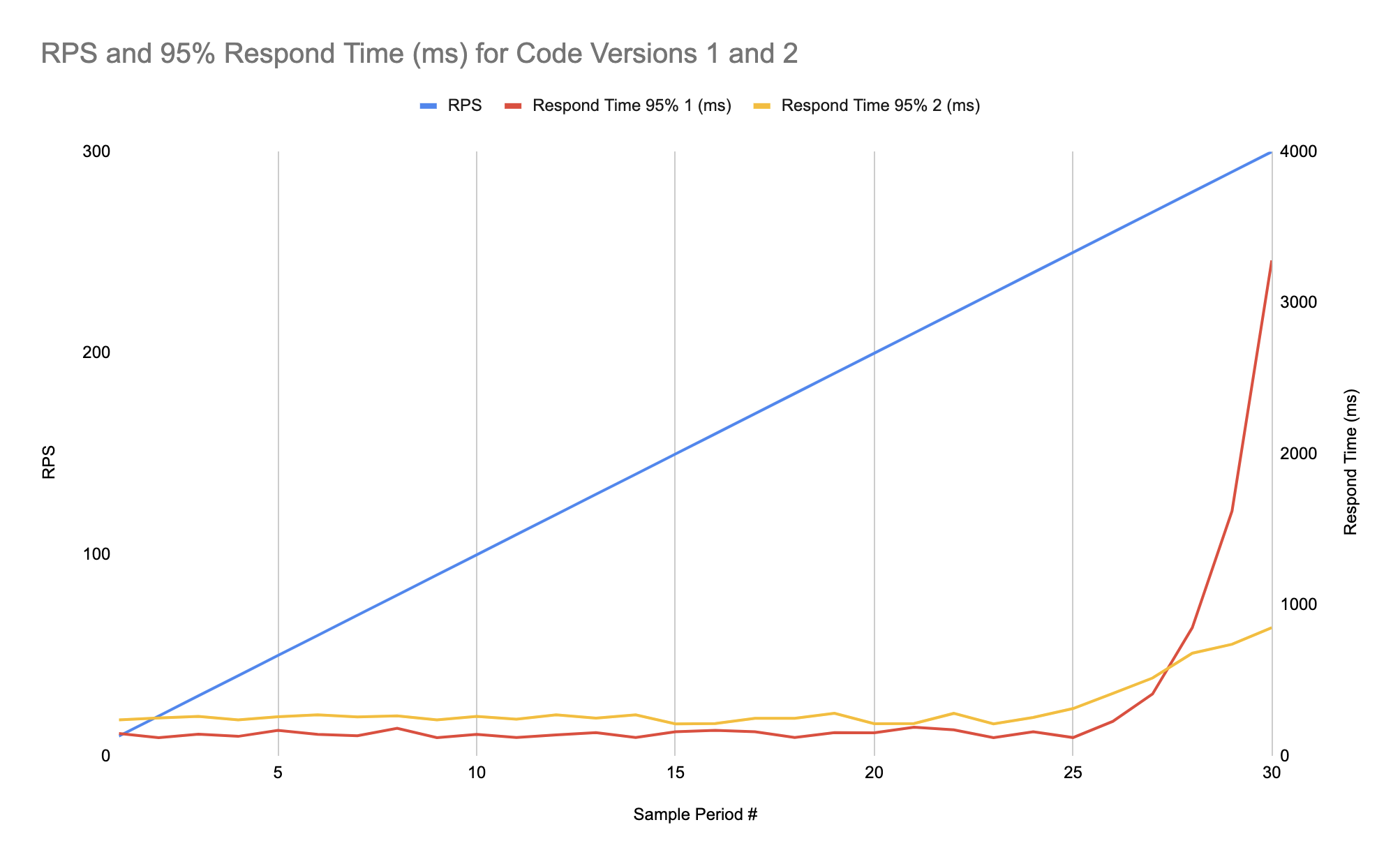
Но как было сказано в разделе «Главные метрики», недостаточно судить основываясь только на одном значении персентили, так что лучше построить графики для нескольких персентилей для каждой версии системы. Вот пример трёх персентилей для одной из версий системы:
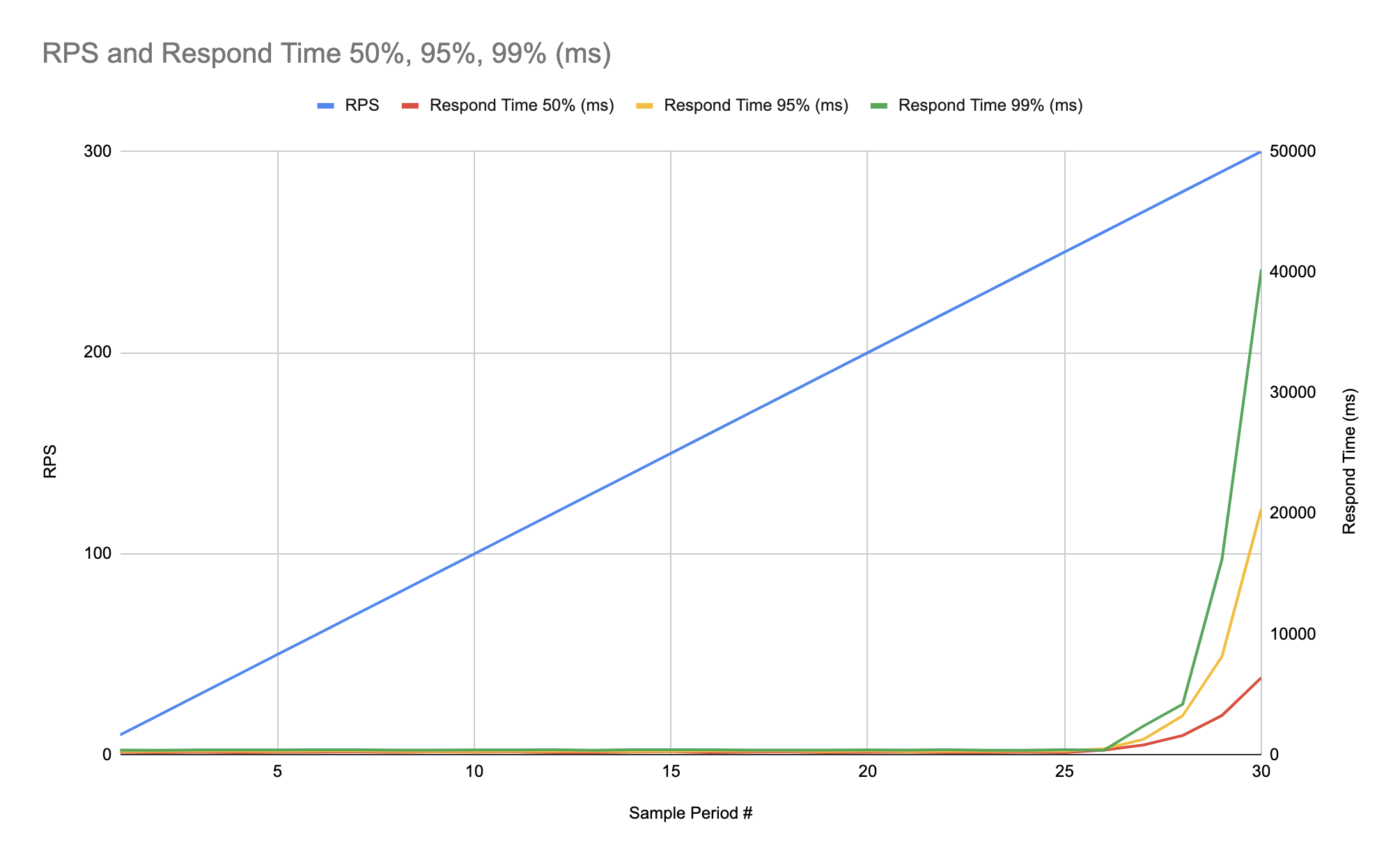
Тесты на стабильность
Если мы обнаружили, что система соответствует ожидаемому объёму нагрузки и корректно работает до некоторых пределов, нам нужно проверить, достаточно ли система стабильна чтобы выдержать нагрузку на большом промежутке времени. Для проверки этого, например, мы можем проверить на утечки памяти. На следующем примере графика нагрузка стабильна, но потребление памяти растёт и растёт, что говорит об утечке и это потребует дополнительного разбора:
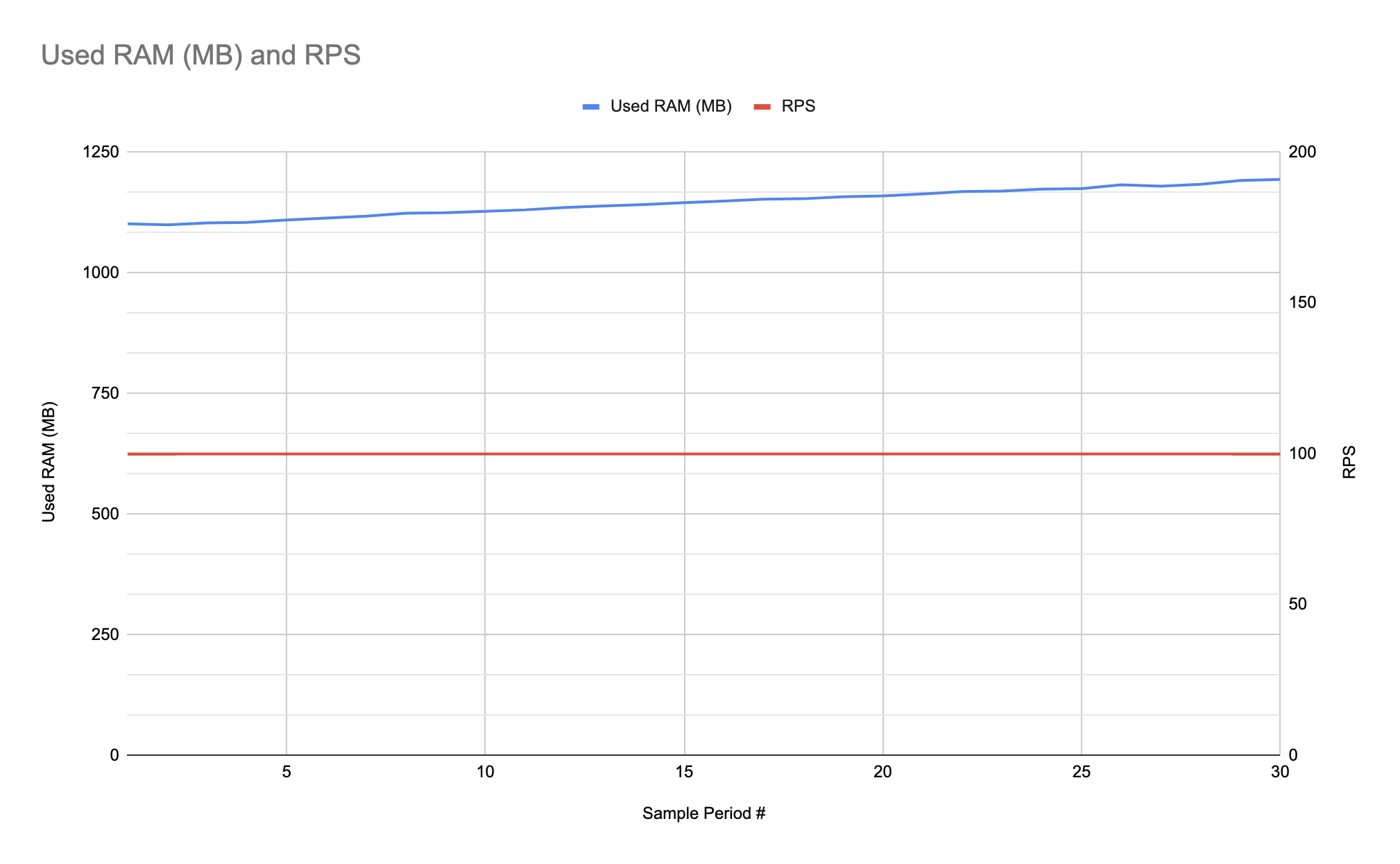
Тесты масштабируемости
Мы определённо хотим знать, что в случае сильно возросшей нагрузки на нашу систему, мы сможем адаптировать её к новой нагрузке просто повышением числа серверов. Для этого выполняются тесты масштабируемости. Например можно взять один показатель (а лучше несколько) и проверить его на разном числе серверов. Для такого теста мы можем получить график, подобный этому:
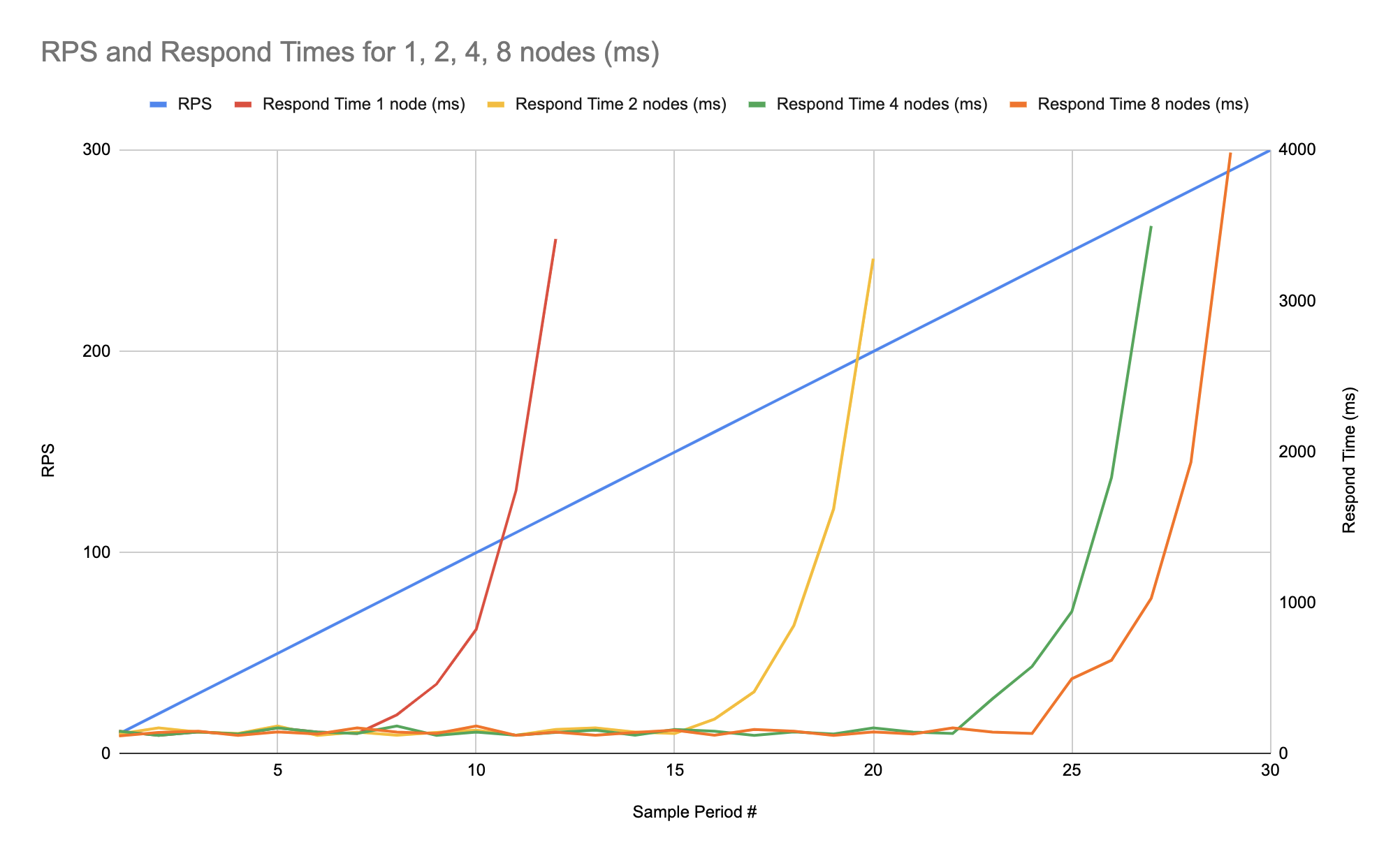
На этом примере графика мы видим что масштабирование от 1 сервера до 2 и 4 достаточно хорошо, но для 8 серверов показатель не сильно отличается от 4-х.
Тесты на резкое повышение нагрузки
Нередкой является ситуация, когда ссылку на нашу систему разместили на каком-нибудь большом сайте или из-за какой-то другой причины, много пользователей тотчас перешли к нам. Наша система должна быть готова к очень резкому росту числа пользователей. Этот тест связан с тестами на масштабируемость и лимиты, но мы должны проверить что наша система не просто масштабируема, а быстро масштабируема, и не только может показывать хорошую производительность при нетипично высокой нагрузке, а быстро адаптироваться к ней.
Тесты на восстановление
Если произошёл какой-то серьёзный отказ в работе, например если один или несколько наших серверов зависли или отключились, наша система система должна быть готова к такому случаю без неприятностей для пользователей. Система должна быстро перенаправить пользователей на оставшиеся сервера и масштабироваться до большего числа серверов если нужно. Когда отказавшие сервера вернутся в строй, система должна быстро быстро вернуться к нормальной работе.
Тесты взаимодействия компонентов
Большая часть сервисов состоит из нескольких компонентов (особенно это критично для микросервисной архитектуры) и ещё один важный тест заключается в проверке того, хорошо или плохо компоненты нашей системы взаимодействуют друг с другом.
Профиль нагрузки
Доклады по теме
Разработка тестовых скриптов и заглушек
Примеры скриптов Apache JMeter
Примеры скриптов Gatling
Плагины Apache JMeter
- JMeter Plugins - большая подборка плагинов для jmeter
Документация
Методика нагрузочного тестирования (МНТ)
Оформление отчета и инструкций
НТ требует весьма большого количества ресурсов и, чтобы эти ресурсы не были потрачены впустую и чтобы извлечь максимум пользы из проведённого НТ, нужен хороший отчёт. Так каковы же критерии хорошего отчёта? Для разных людей польза от отчёта зависит от наличия ответов на соответствующие вопросы:
- Для менеджера — насколько система соответствует требованиям, есть ли запас и какая ситуация может вызвать проблемы с системой?
- Для DevOps — есть ли слабые места системы со стороны инфраструктуры.
- Для разработчиков — есть ли слабые места системы со стороны кода.
- Для НТ инженера — какие инструменты НТ с какими настройками использовались, какой сценарий использовался, на какой конфигурации инфраструктуры проводился тест. Все эти знания в том числе для того чтобы можно было воспроизвести сценарий при каких-либо изменениях кода или инфраструктуры для сравнения.
Нет отчёта — НТ впустую!
Запуск тестов
Сбор и анализ метрик/логов
Паттерны поведения системы под нагрузкой
«Пила»
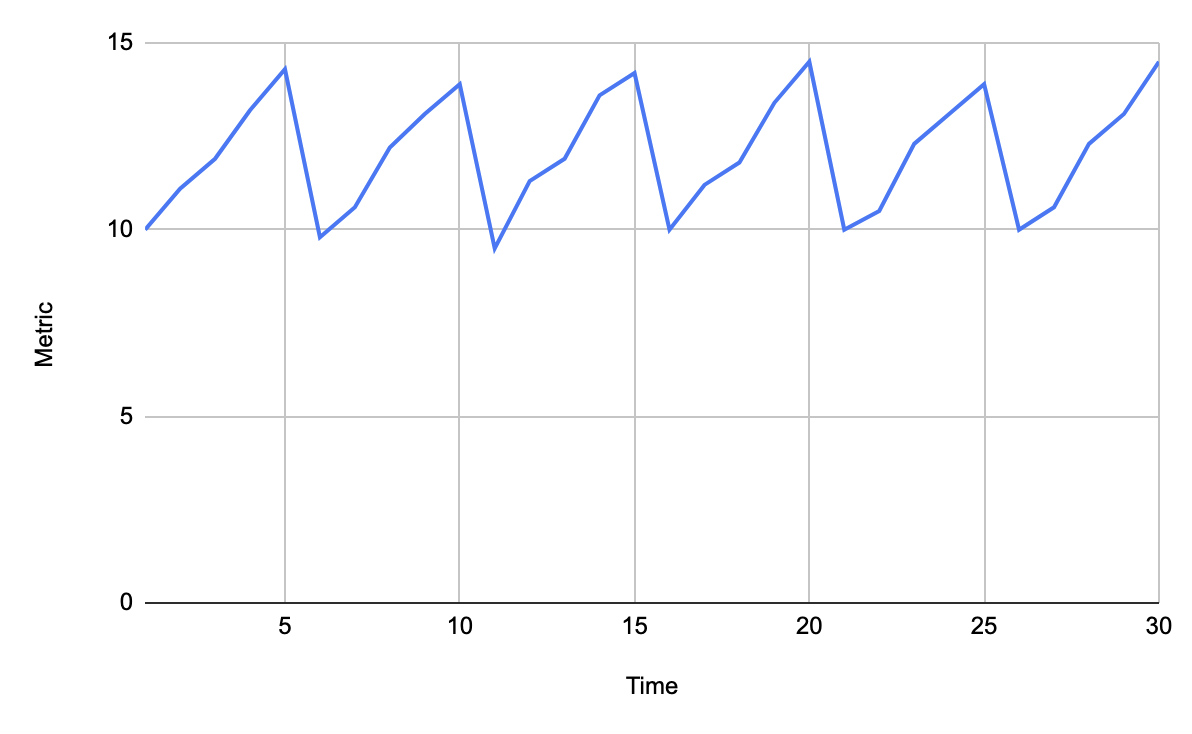
Скачки показателя значимо вверх/вниз, может говорить о насыщении какого-то ресурса до предела и падении ряда агентов, поднятии новых и повторе ситуации.
«Полка»
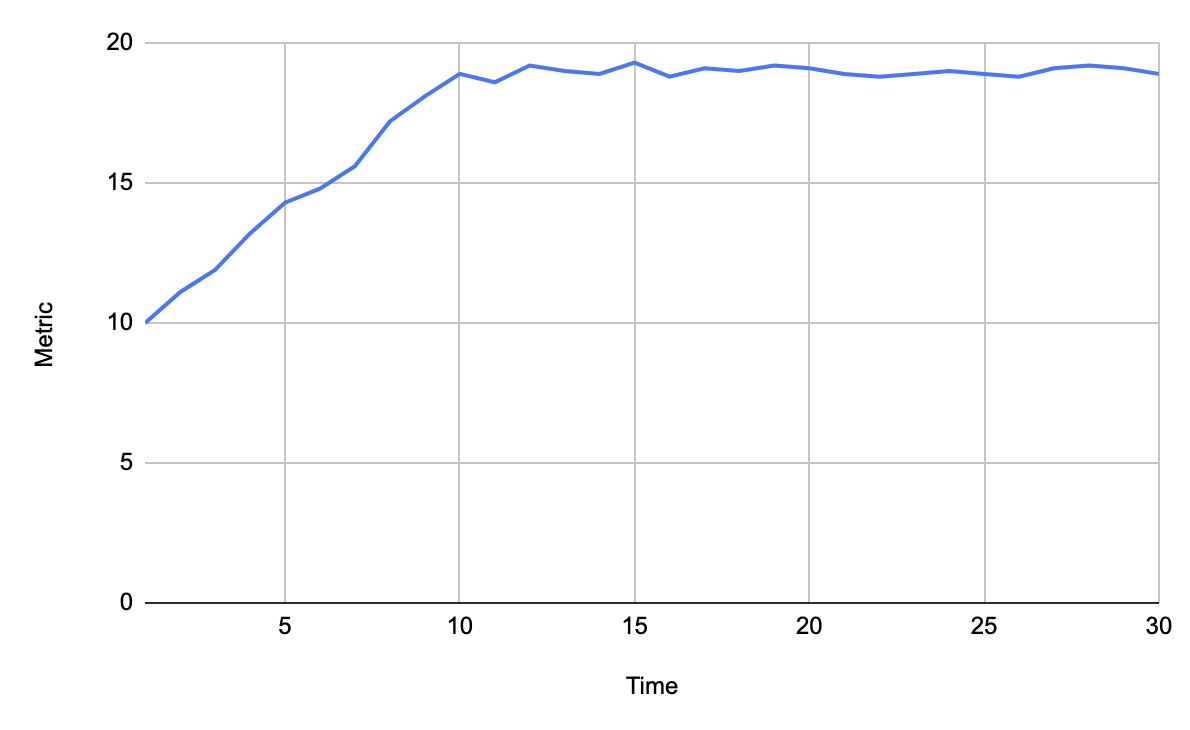
Может говорить о том, что мы достигли какого-то предела и дальше система не справляется, хотя и не падает. Здесь надо ещё смотреть состояние генераторов нагрузки, может больше этого предела и не грузят они и это не ошибка а просто достижение уровня возможного. Ещё это может быть просто предельное значение, выше которого подняться в принципе невозможно, например загрузка CPU, такие случаи требуют особого внимания.
«Всплеск»
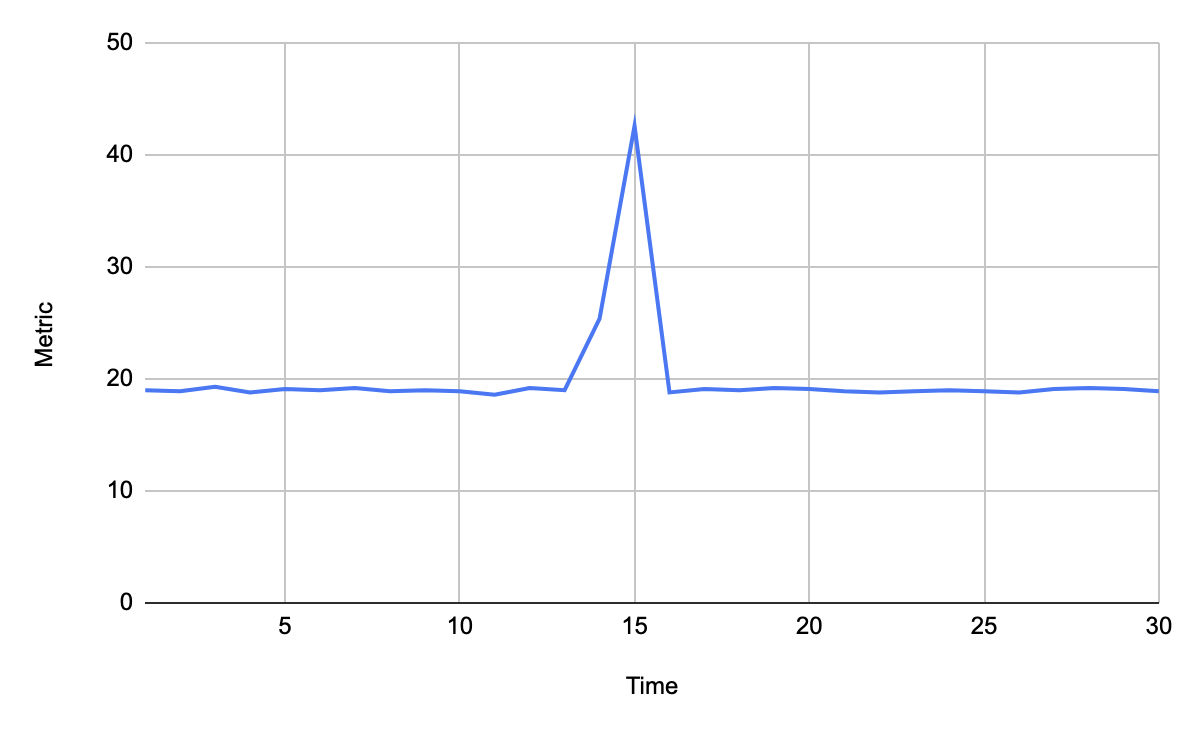
Просто резкий скачок, причину которого может быть нужно изучить. Это может быть например просто внезапно запустившаяся сборка мусора.
Резкое падение
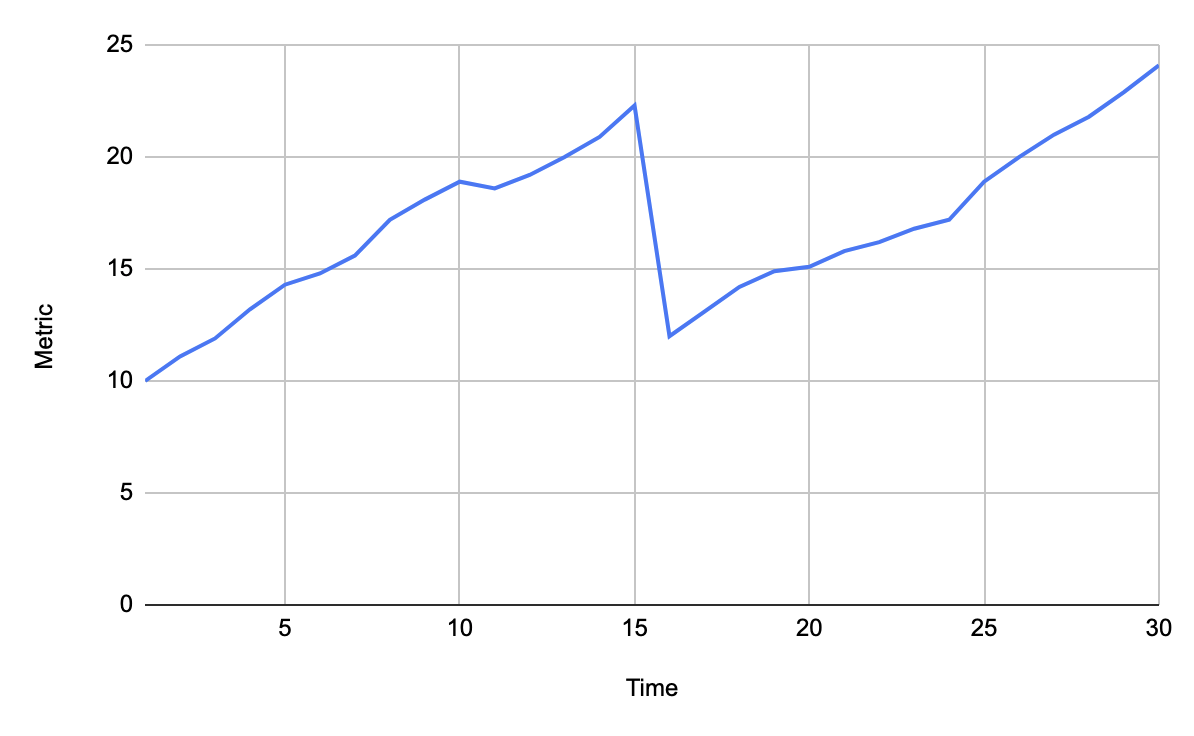
Например в начале теста при постепенном увеличении нагрузки может умереть один из воркеров, генерирующих трафик. Или это может быть график общего числа RPS для всего кластера и может отказать один сервер.
Плавная деградация
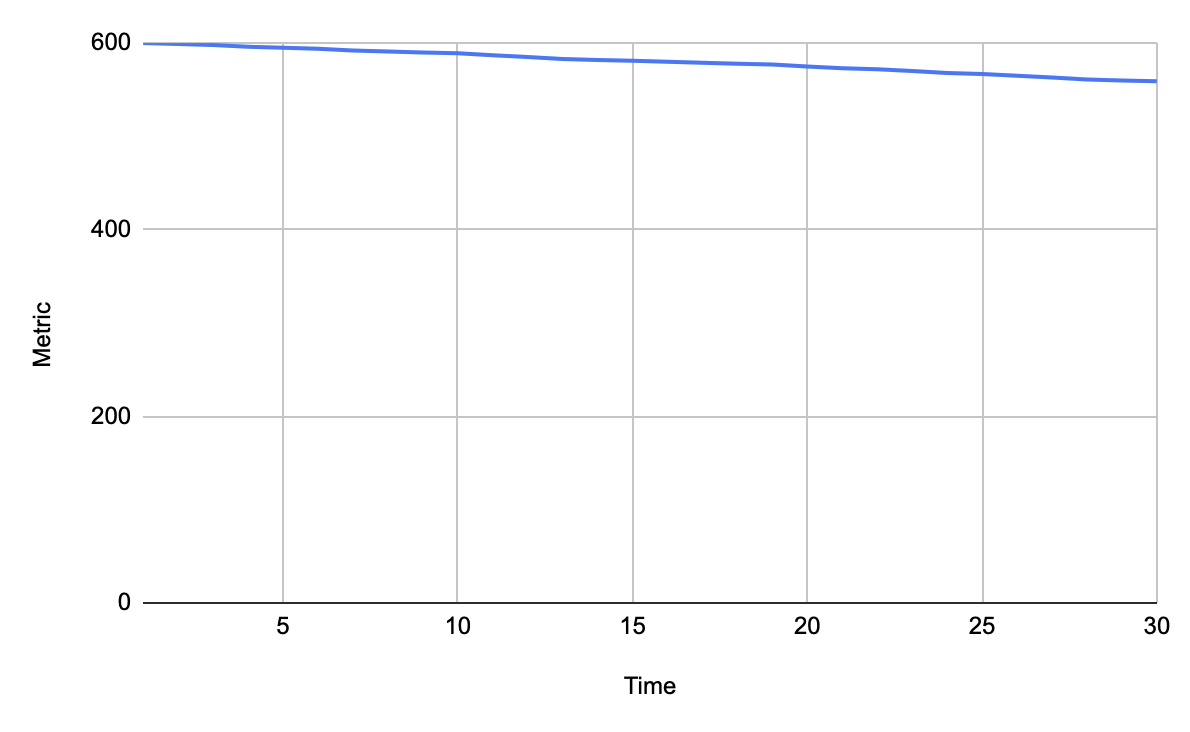
Это может быть например график RPS на сервере и они по какой-то причине при стабильной нагрузке могут снижаться.
Линейный/нелинейный рост связанных метрик
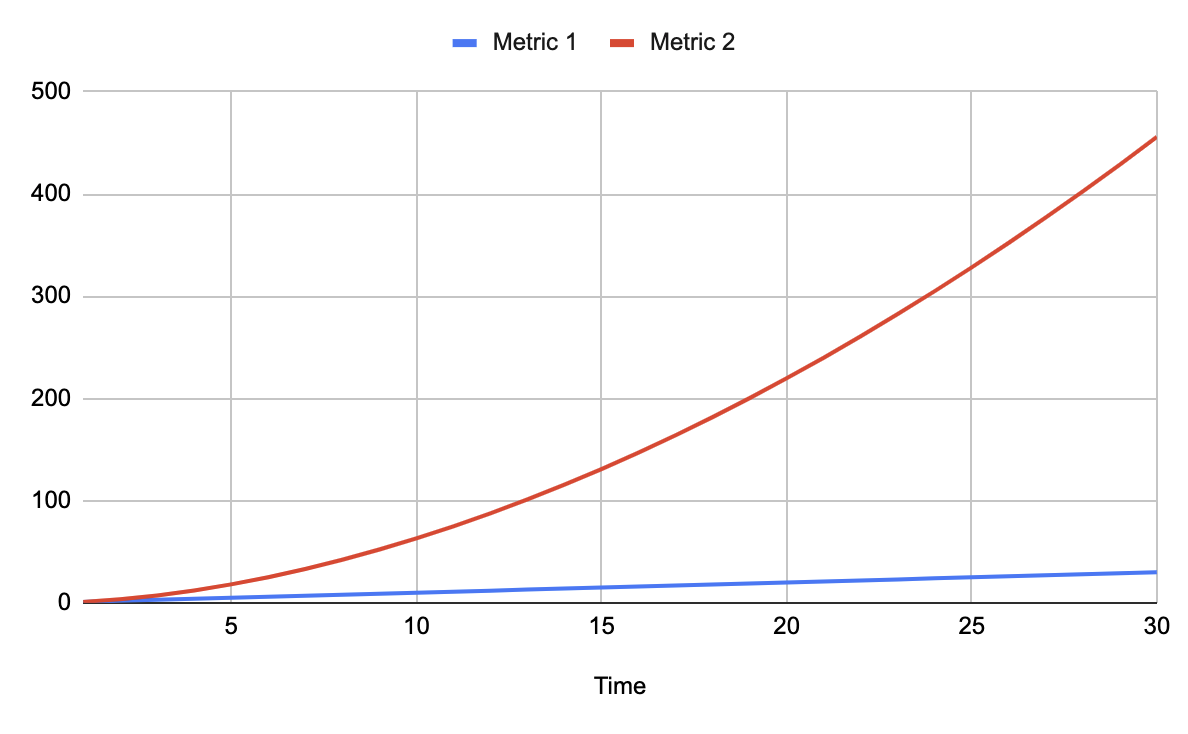
Это связано с масштабированием. Если число клиентов растёт например линейно, лучше бы чтобы уровень нагрузки подсистем тоже рос хотя бы линейно, но никак не быстрее на несколько степеней. Ну и здесь самое время вспомнить про сложность алгоритмов: O(n), O(log n), O(n^2) и подобное.
Генерация тестовых данных
Изучение работы системы
Настройка стенда
Инструменты нагрузочного тестирования
Мониторинг
Подготовка рабочего места
Автоматизация
Доклады
- Автоматизация НТ дешево и больно Кирилл Юрков - Jenkins, JMeter и Grafana
- Готовый шаблон автоотчеты в JMeter + большой дашборд - Confluence, JMeter и Grafana тестовые тренды и переход к тесту по ссылке.